
|
Don't miss this! If you are an SCS customer with a maintenance contract for Layout-8000, you are entitled to this release at no additional cost. It is available for download as of August 5, 2015. If you need help, call us and ask for Layout support. The newspaper business is changing, and we must help our customers with those changes. To improve efficiency, newspapers are consolidating. Newspaper groups are building design centers to help streamline newspaper design and production. We have been releasing incremental changes in Layout-8000 Version 14 since March of last year. All together the changes since then support a huge change in orientation. It's been a year in the making, but for newspapers using SCS’s Layout-8000 to dummy the display ads into their printed products, the new feature set available in Version 15, launching Aug. 5, 2015, will be more than worth the wait. This major upgrade to the industry's leading ad dummying software includes important advancements in security and redundancy, making it a whole lot less likely that a single point of failure - a power outage, equipment breakdown, network hiccup, etc. - will interrupt production workflow. For newspaper groups with consolidated design centers, the application has been thoroughly reengineered for the very different workflows necessary in that kind of environment, including
Multi-product management The image below shows what you will see when you startup Layout-8000 and get ready to select a product to dummy. 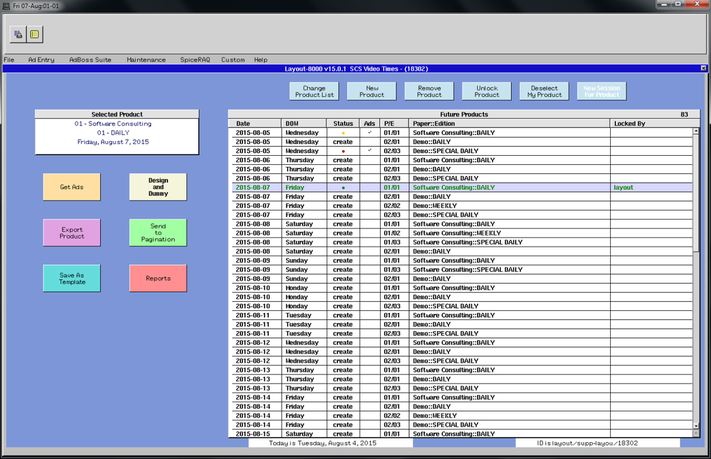 Layout-8000 knows which products you are likely to be dummying today, and it presents them to you as choices. It lets you know which ones have ads waiting, which ones have been started and which have not, which ones are completed and who is or has been working on each. Attention design center managers: this makes an easy place for you to keep track of the schedule and the progress for the day. You might want or need to start work on a new product before you have finished the last one. This is now no problem; you can select a new product and work on it in a new window. You can switch back and forth with no need to close and reopen products each time. 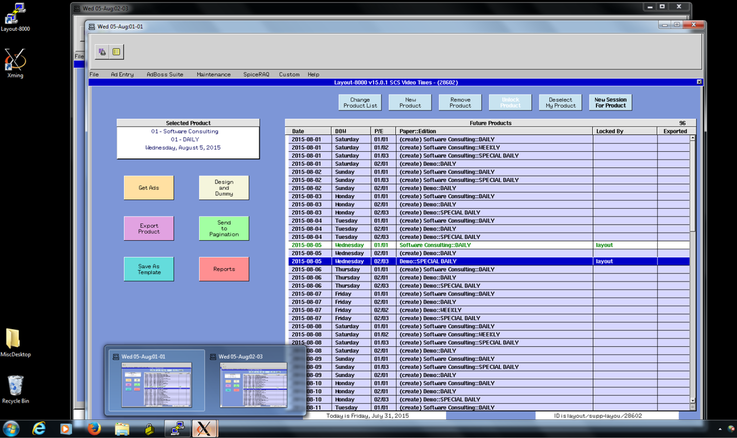 Busy work reduction and mobile access to reports We are working hard to reduce and simplify repetitive clerical tasks. If there is a series of steps that are always performed at a particular point in the dummying process (e.g. when a product is “sent to pagination”), these steps can be configured once and executed with a single mouse click. One of these repetitive steps is generating and distributing a Final Report for a product after it has been sent to pagination. This report can be emailed to users throughout the organization who need a copy. The email list details can be set up once and invoked with a mouse click when needed. With Version 15 this can be automated further. Instead of requiring the Layout user to distribute the report, users of the report can retrieve it on any mobile device or workstation via self-service just as they can retrieve page dummies (Note: this feature requires the optional module PGLAdBoss). The Layout operator does not need to take the time to print or email copies. Ad placement consistency Version 15 includes a learning module, LayoutHistoryAdBoss, which remembers where the ads of various advertisers for various products are consistently placed. It uses this data to provide a ranked set of placement recommendations. Improved high availability This is a critical issue, and it is a sufficient reason in and of itself to install Version 15. Why is high availability something Layout-8000 users need to think about? The simple answer is that if Layout-8000 were somehow to be unavailable, its users would be in a world of hurt. And it is not just about ad dummying. At almost every installation, Layout-8000 provides important interfaces (middleware) among advertising order entry systems, production systems and pagination systems. The requirements for this middleware are as complex as any of the interfaces among applications in newspapers. What comes in from a rate card based insertion order goes out from Layout-8000 as an edition design with precise geometric locations for ads, etc. It's mission critical and, without it, getting out an edition on time is nearly impossible. As more and more products are dummied in large design centers, there is more risk of workflow disruption if a centralized server fails. Most newspapers back up their data processing oriented ad scheduler with Layout-8000's production oriented scheduler by constantly feeding current insertion order transactions to it. They depend on it. SCS takes high availability very seriously. We are changing our approach to this for Layout-8000 from a nightly full snapshot to a combination of the nightly snapshot with a technique called log shipping. We have used the full snapshot approach in Layout-8000 for numerous years. Recovery takes you back to the state when the last snapshot was done. Snapshots taken the night before lose the session work back to the nightly backup should there be some sort of failure. Since Layout-8000 almost never fails, this method has provided adequate reliability. As design centers grow, however, the possibility of a server failure and its impact on multiple publications becomes more serious. SCS's other advertising applications don’t rely on snapshots alone to provide high availability. To meet the needs for even higher availability with larger active computational states, they keep two (or more) application environments in sync in near real time. You can switch from one to the other and be assured you will lose little, if anything, when an application server fails. This is done by sending copies of all changed records from the active environment to be almost immediately applied to a backup environment (this is called log shipping). Log shipping is a reliable mechanism for building recoverable databases. Layout-8000 Version 15 is being deployed with log shipping. Read this article we have posted on LinkedIn at http://bit.ly/1IHgyEe (link is external) for the technical details - especially if you are using VMWare. For specifics about how this technology is deployed for Layout-8000, see the diagrams at the end of this article. A special thanks to the folks at Gannett for sharing how well they use our high availability technology and for challenging us to make it better. We also appreciate having the many new Gannett publications using Layout-8000. And thank you, Kris Julius of Lee Enterprises for sharing your insights for building well-managed corporate design centers. You are teaching us how to do it better. 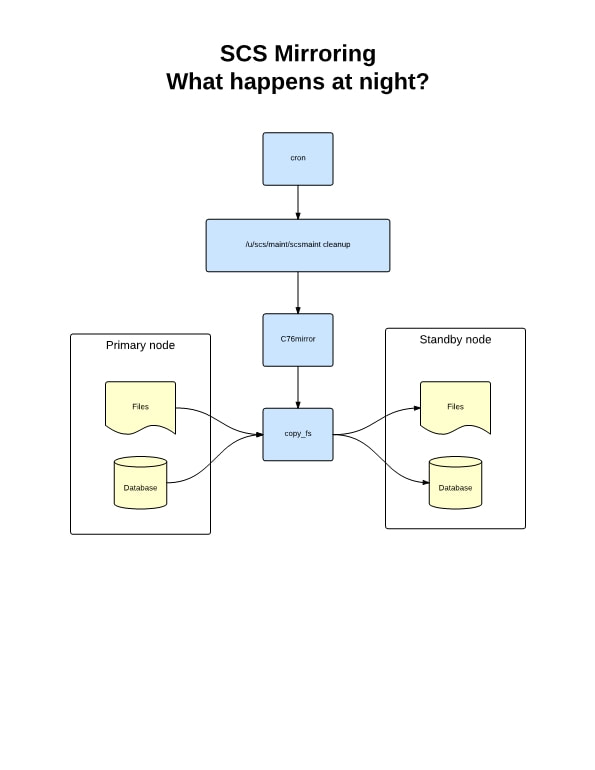 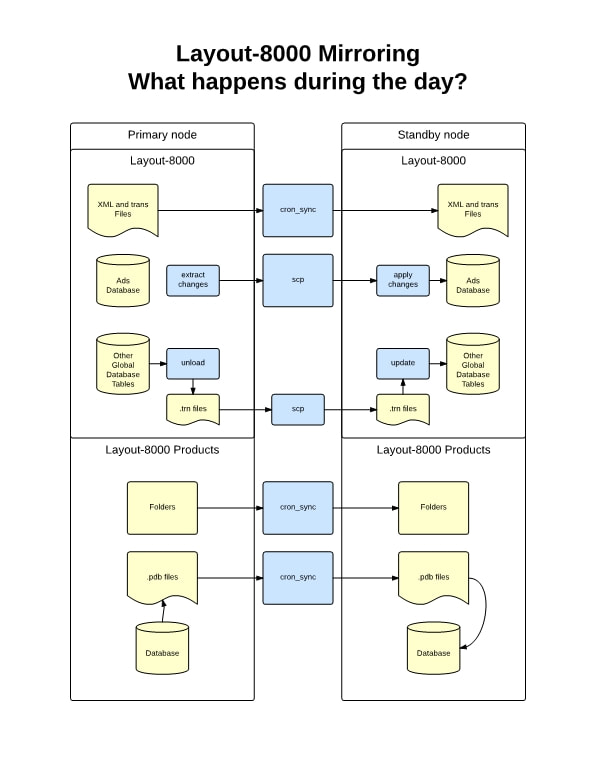 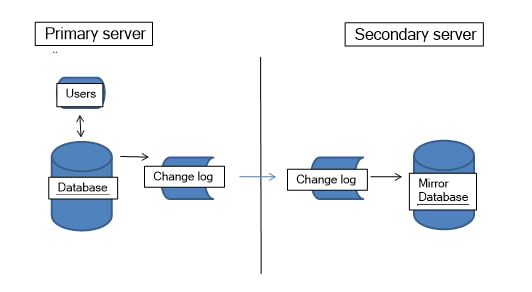 Why is high availability something users of any mission-critical software need to think about? The simple answer is that if the application is unavailable, its users would be in a world of hurt. Software Consulting Services, LLC (SCS) takes high availability very seriously. Pay special attention if you are using VMWare.
One typical approach for data processing applications is to provide recovery from failures by taking snapshots. Snapshots come in two varieties. Full snapshots are those where an entire copy is made of the current state, i.e. all data managed by the application. Delta snapshots copy over only the differences between one context and the prior one. Using the full snapshot approach, recovery takes you back to the state when the last snapshot was done. Snapshots taken the night before lose the session work back to the nightly backup should there be some sort of failure. For applications that fail almost never, this method usually provides adequate reliability. Delta snapshots are different. Like a full snapshot, you are able to get back to the state of the latest snapshot. Unfortunately, the path there involves already having a full backup copy and then applying snapshot deltas one at a time until you have the state of the computation as up to date as it can be. Delta snapshots are tricky. And as the VMWare documentation (1025279) for "Best practices" states, "Snapshots are not backups. A snapshot file is only a change log of the original virtual disk. Therefore, do not rely on it as a direct backup process." For snapshots to work, databases need to be quiescent when a snapshot is made. Usually, this implies that the service being provided by an application is interrupted. Choices need to be made that trade mean time to recover (MTTR) against the cost of service interruption. Thus you hear the term "nightly backup" rather than "15-minutes-ago backup." To meet the needs for even higher availability with larger active computational states, our applications keep two (or more) application environments in sync in near real time. We call this “mirroring”. You can switch from one to the other and be assured you will lose little if anything when an application server fails. This is done by log shipping. Log shipping is a reliable mechanism for building recoverable databases. Here is how it works. Log shipping is built into SCS's data management subsystem. Two separate applications environments are kept in sync. When a record is updated in the primary environment, a transaction is made and passed to the secondary environment. The secondary is always running so it is active and sort of "on standby". It can take over the work by a simple "make primary" command. We contrast active standby availability to a "powered off" backup machine. These are in no way the same in terms of disaster recovery. It is important that the primary and secondary environments have nothing in common but their network connection. Anything that fails with one should never impact the other. This is called "shared nothing servers." We don't even put these servers on the same UPS! Nothing is shared, not even the underlying data management algorithms. The transmitted log-based transactions have their own updating, consistency and validation logic. This is designed to be both more bullet proof and idiot proof. Just as a side note – With stable software systems, the actual need for switching to a secondary server may be so rare that we recommend that switching take place on a scheduled basis. Without practicing, it is probable that during an emergency more problems will be created. (You should read the VMWare recovery procedure if you want a really good scare.) I really wish more attention were paid to recovery and high availability issues. Just last month we were helping one of our customers and we found their secondary server was last updated in 2008. An untested and unpracticed disaster recovery plan is no recovery plan at all. The primary and secondary servers don't need to be in the same location, although since server class technology is so inexpensive these days, both are likely to be deployed in the same server room. (They might be separate VMs on separate servers.) Should enhanced disaster recovery be desired, additional secondary servers can be deployed in remote secure locations. All the articles and their links starting from this URL are relevant if you wish to dig deeper. |
SCS Team
Articles in the SCS Blog are written by SCS employees and associated news outlets. Archives
June 2021
Categories
�
|
|
Software Consulting Services, LLC
252 Brodhead Road, Suite 400 Bethlehem, PA 18017 |
Our Privacy Policy
Copyright 2024 Software Consulting Services, LLC
Copyright 2024 Software Consulting Services, LLC